Large Language Models (LLMs) have the potential to automate and reduce the workloads of many types, including those of cybersecurity analysts and incident responders. But generic LLMs lack the domain-specific knowledge to handle these tasks well. While they may have been built with training data that included some cybersecurity-related resources, that is often insufficient for taking on more specialized tasks that require more up to date and, in some cases, proprietary knowledge to perform well—knowledge not available to the LLMs when they were trained.
There are several existing solutions for tuning “stock” (unmodified) LLMs for specific types of tasks. But unfortunately, these solutions were insufficient for the types of applications of LLMs that Sophos X-Ops is attempting to implement. For that reason, SophosAI has assembled a framework that utilizes DeepSpeed, a library developed by Microsoft that can be used to train and tune the inference of a model with (in theory) trillions of parameters by scaling up the compute power and number of graphics processing units (GPUs) used during training. The framework is open source licensed and can be found in our GitHub repository.
While many of the parts of the framework are not novel and leverage existing open-source libraries, SophosAI has synthesized several of the key components for ease of use. And we continue to work on improving the performance of the framework.
The (inadequate) alternatives
There are several existing approaches to adapting stock LLMs to domain-specific knowledge. Each of them has its own advantages and limitations.
| Approach | Techniques applied | Limitations |
| Retrieval Augmented Generation |
|
|
| Continued Training |
|
|
| Parameter Efficient Fine-tuning |
|
|
To be fully effective, a domain expert LLM requires pre-training of all its parameters to learn the proprietary knowledge of a company. That undertaking can be resource intensive and time consuming—which is why we turned to DeepSpeed for our training framework, which we implemented in Python. The version of the framework that we are releasing as open source can be run in the Amazon Web Services SageMaker machine learning service, but it could be adapted to other environments.
Training frameworks (including DeepSpeed) allow you to scale up large model training tasks through parallelism. There are three main types of parallelism: data, tensor, and pipeline.
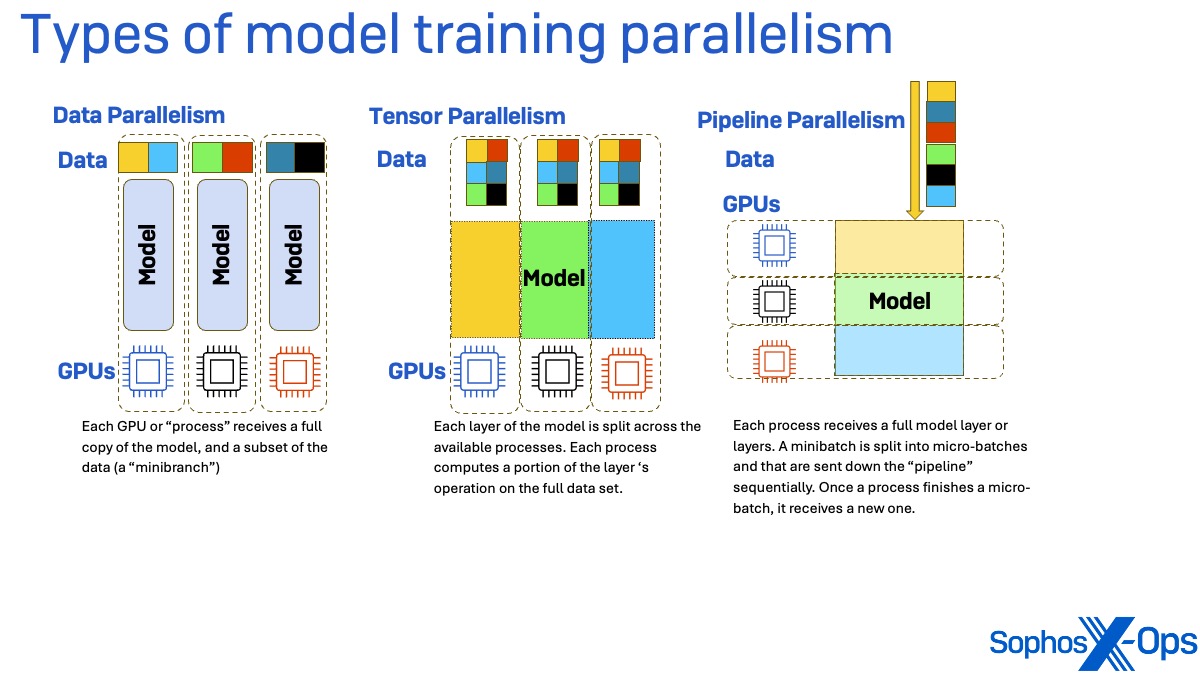
In data parallelism, each process working on the training task (essentially each graphics processor unit, or GPU) receives a copy of the full model’s weights but only a subset of the data, called a minibatch. After the forward pass through the data (to calculate loss , or the amount of inaccuracy in the parameters of the model being used for training) and the backward pass (to calculate the gradient of the loss) are completed, the resulting gradients are synchronized.
In Tensor parallelism, each layer of the model being used for training is split across the available processes. Each process computes a portion of the layer ‘s operation using the full training data set. The partial outputs from each of these layers are synchronized across processes to create a single output matrix.
Pipeline parallelism splits up the model differently. Instead of parallelizing by splitting layers of the model, each layer of the model receives its own process. The minibatches of data are divided into micro-batches and that are sent down the “pipeline” sequentially. Once a process finishes a micro-batch, it receives a new one. This method may experience “bubbles” where a process is idling, waiting for the output of processes hosting earlier model layers.
These three parallelism techniques can also be combined in several ways—and are, in the DeepSpeed training library.
Doing it with DeepSpeed
DeepSpeed performs sharded data parallelism. Every model layer is split such that each process gets a slice, and each process is given a separate mini batch as input. During the forward pass, each process shares its slice of the layer with the other processes. At the end of this communication, each process now has a copy of the full model layer.
Each process computes the layer output for its mini batch. After the process finishes computation for the given layer and its mini batch, the process discards the parts of the layer it was not originally holding.
The backwards pass through the training data is done in a similar fashion. As with data parallelism, the gradients are accumulated at the end of the backwards pass and synchronized across processes.
Training processes are more constrained in their performance by memory than processing power—and bringing on more GPUs with additional memory to handle a batch that is too large for the GPU’s own memory can cause significant performance cost because of the communication speed between GPUs, as well as the cost of using more processors than would otherwise be required to run the process. One of the key elements of the DeepSpeed library is its Zero Redundancy Optimizer (ZeRO), a set of memory utilization techniques that can efficiently parallelize very large language model training. ZeRO can reduce the memory consumption of each GPU by partitioning the model states (optimizers, gradients, and parameters) across parallelized data processes instead of duplicating them across each process.
The trick is finding the right combination of training approaches and optimizations for your computational budget. There are three selectable levels of partitioning in ZeRO:
- ZeRO Stage 1 shards the optimizer state across.
- Stage 2 shards the optimizer + the gradients.
- Stage 3 shards the optimizer + the gradients + the model weights.
Each stage has its own relative benefits. ZeRO Stage 1 will be faster, for example, but will require more memory than Stage 2 or 3. There are two separate inference approaches within the DeepSpeed toolkit:
- DeepSpeed Inference: inference engine with optimizations such as kernel injection; this has lower latency but requires more memory.
- ZeRO Inference: allows for offloading parameters into CPU or NVMe memory during inference; this has higher latency but consumes less GPU memory.
Our Contributions
The Sophos AI team has put together a toolkit based on DeepSpeed that helps take some of the pain out of utilizing it. While the parts of the toolkit itself are not novel, what is new is the convenience of having several key components synthesized for ease of use.
At the time of its creation, this tool repository was the first to combine training and both DeepSpeed inference types (DeepSpeed Inference and ZeRO Inference) into one configurable script. It was also the first repository to create a custom container for running the latest DeepSpeed version on Amazon Web Service’s SageMaker. And it was the first repository to perform distributed script based DeepSpeed inference that was not run as an endpoint on SageMaker. The training methods currently supported include continued pre-training, supervised fine-tuning, and finally preference optimization.
The repository and its documentation can be found here on Sophos’ GitHub.